
I don't necessarily live and die by Gartner research, but one thing I think they've really nailed is the concept of the Hype Cycle, the idea that new technologies see a mad rush of optimism, followed by a period of disillusionment as it turns out the new technology isn't magic (shocker!), followed by people actually sitting down and figuring out what the thing can actually be useful for.
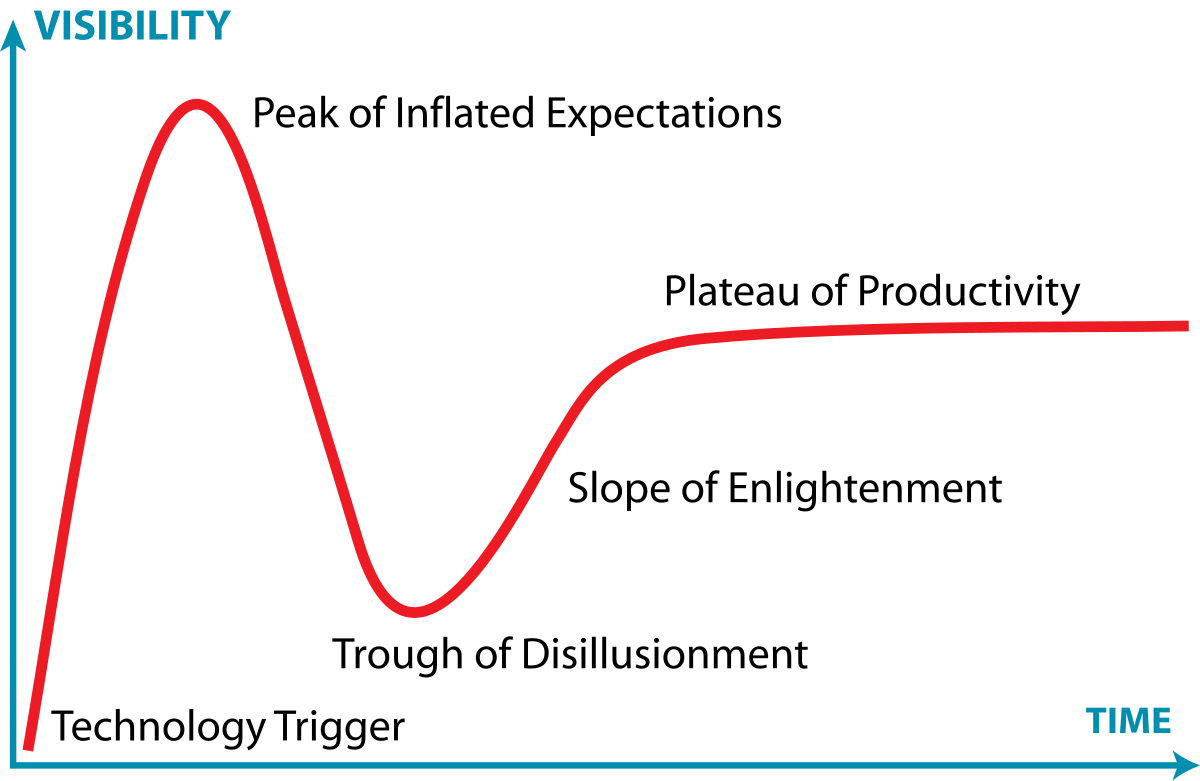
A graph of the hype cycle, as described above
The trajectory of AI over the last couple of years is a perfect encapsulation of this. It seemed like every piece of enterprise software rushed to jam a chatbot into its UI in 2024, with mostly disappointing results. This led a lot of users to label AI features as useless, at best.
The biggest problem is that they didn't do anything. They could write and edit some copy, answer some general knowledge questions (that you'd need to fact check), and that's about it.
The problem was access. Almost all LLMs are based on a set of training data, which is usually at least several months old, and based on publicly available information. All well and good, but they didn't have my information. They also weren't able to reach into any other systems and get data out. As the base case, this is still true.
For example, let's ask Claude Desktop what my day looks like:
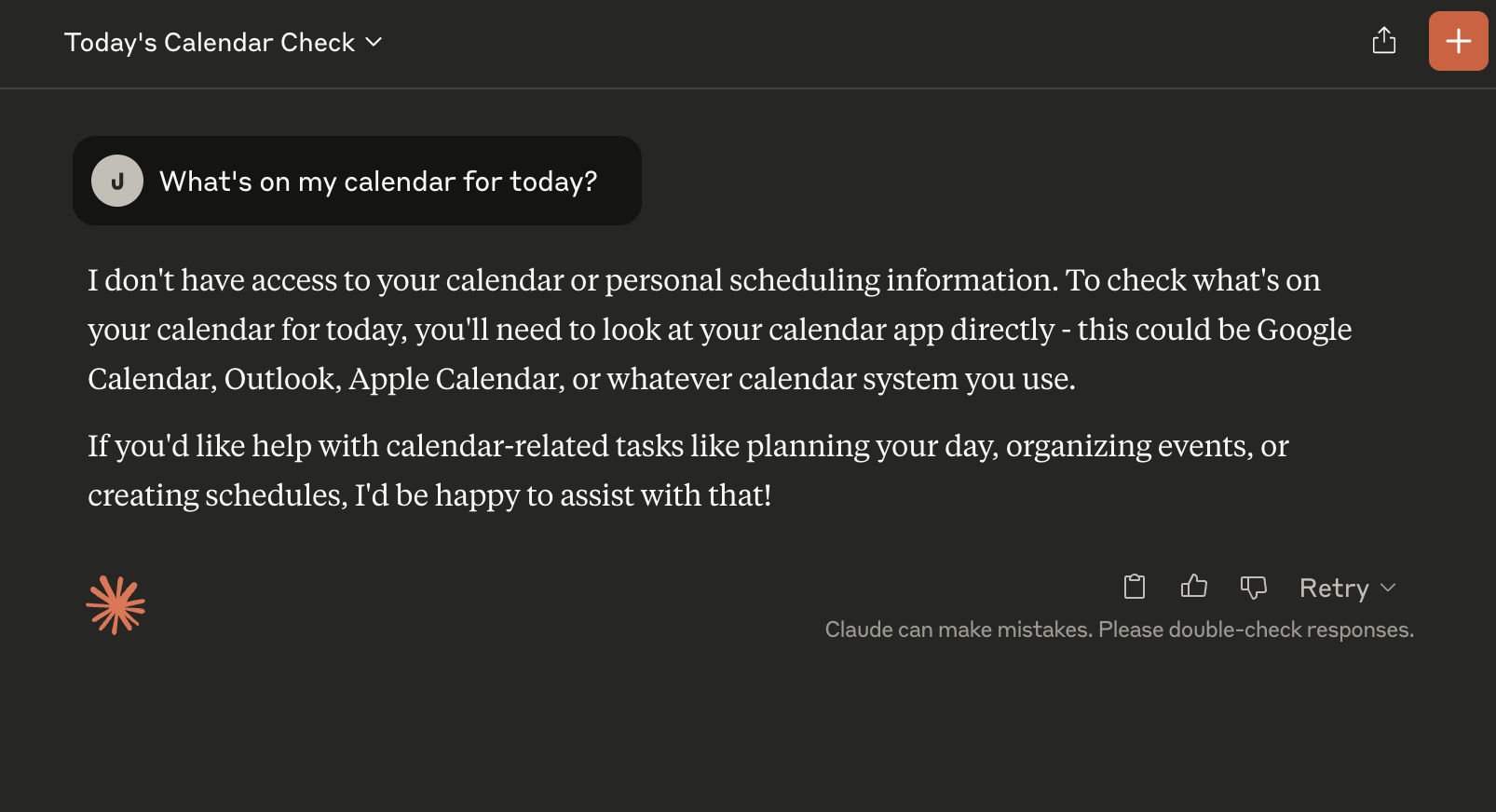
Screenshot showing Claude with no personal information
Claude explains to me how to look at a calendar. Gee, thanks. This is the LLM equivalent of, "Are your legs broken? Go get it yourself."
To be fair, it's being helpful as it's able. Claude simply can't reach into my calendar and see my events. My schedule for today isn't within its context, so there's not a lot that it can do.
But what if it could? What if we enabled an integration with the Google Calendar API?
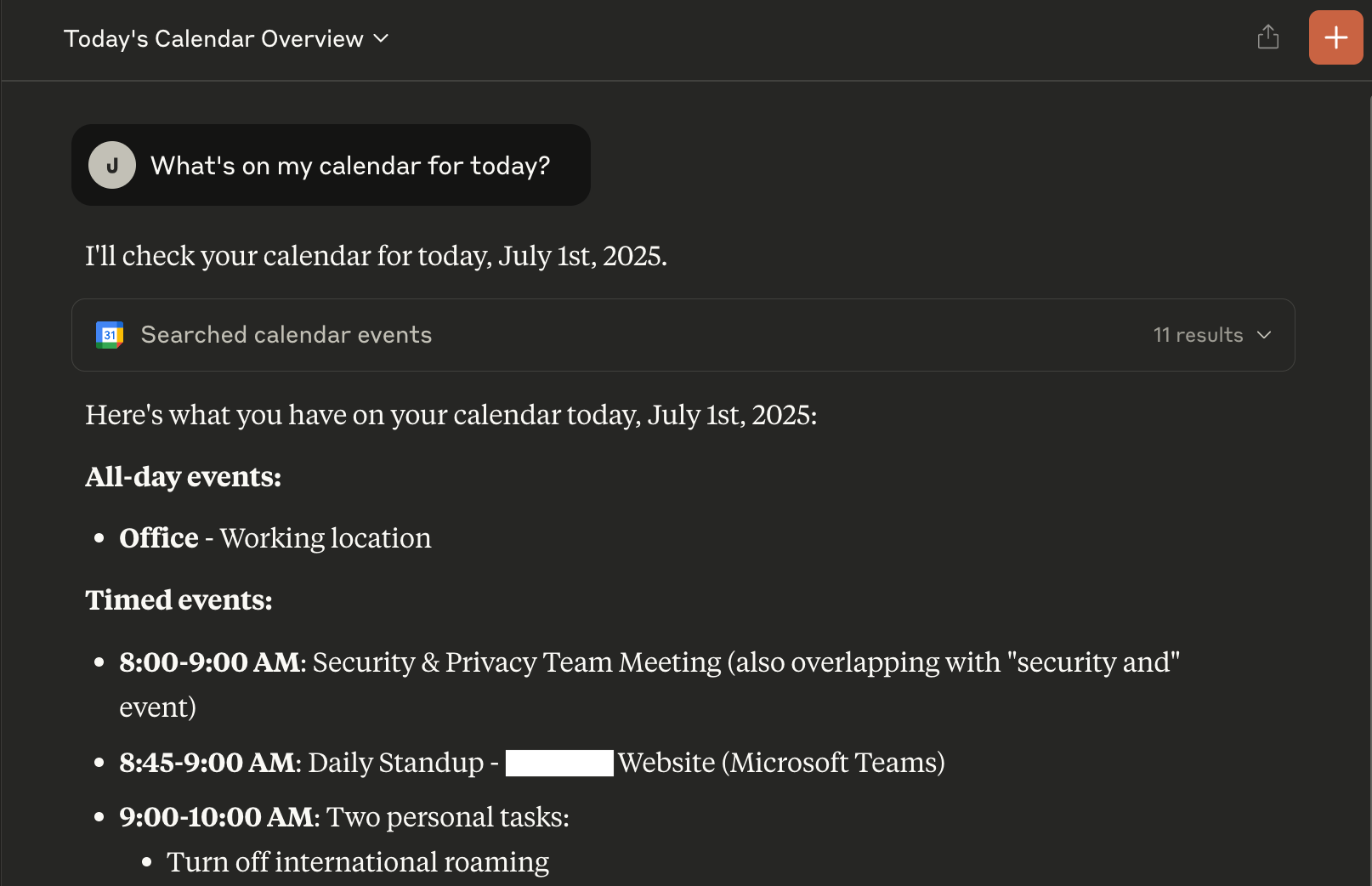
Screenshot of Claude summarizing a day's schedule from Google Calendar
Bingo! Claude now has this tool in its context, so it figures out how to go get my information. We've just gone from a standard language model to an "agentic" one that can reason and take actions on our behalf.
This is great, but when we think about all the apps and services in the world that we might like to connect in this way, we find that GPT providers are in for a lot of work. Everything has its own API, data model, permissions, protocols, credentials, etc.
It reminds me a little of connecting peripherals to your computer back in the old days. Your printer, keyboard, monitor, network, modem, and everything else used some proprietary connector. The back of your computer was insane and your closet looked like a nest of snakes.

Picture of a pile of cables.
On a modern device, this is largely solved with one cable standard.

Picture of USB-C cable
In late 2024, Anthropic proposed an open standard intended to be the equivalent of USB-C for connecting things to GPTs. They named this Model Context Protocol since it injects Context into a Large Language Model, and presumably also because it references the kinda goofy-looking nemesis from Tron.
This was a savvy move, and a win for users, developers, open standards, and Anthropic. At the time, their rival OpenAI was working on individually integrating major services, old-peripheral style, since this suited their dominant market position. Creating and releasing an open standard made Anthropic's Claude more useful, growing its market share, and lead to rapid integration of third party tools. In March of 2025, OpenAI switched to officially supporting MCP, and Google has backed the protocol for Gemini as well. MCP has quickly become the de facto standard for exposing data and functionality to a LLM.
MCP Explained
But what is MCP? You don't really need to understand the details of how MCP works in order to use it, but I'm the type of person that took apart things as a kid to see how they worked, so let's peek under the hood just a little.
The protocol defines a few types of participants working together:
- A host is some program that wants to use some kind of service. This is usually your LLM application, like Claude Desktop, or maybe an IDE. This is probably this system you're interacting with to use the AI, flipping the usual use of the words 'host' and 'client' for us web developers
- A client is a bit of code within the host that interfaces with the LLM and sends MCP requests when called for
- A server is a bit of code that handles those requests and interfaces with the actual service being integrated into the LLM
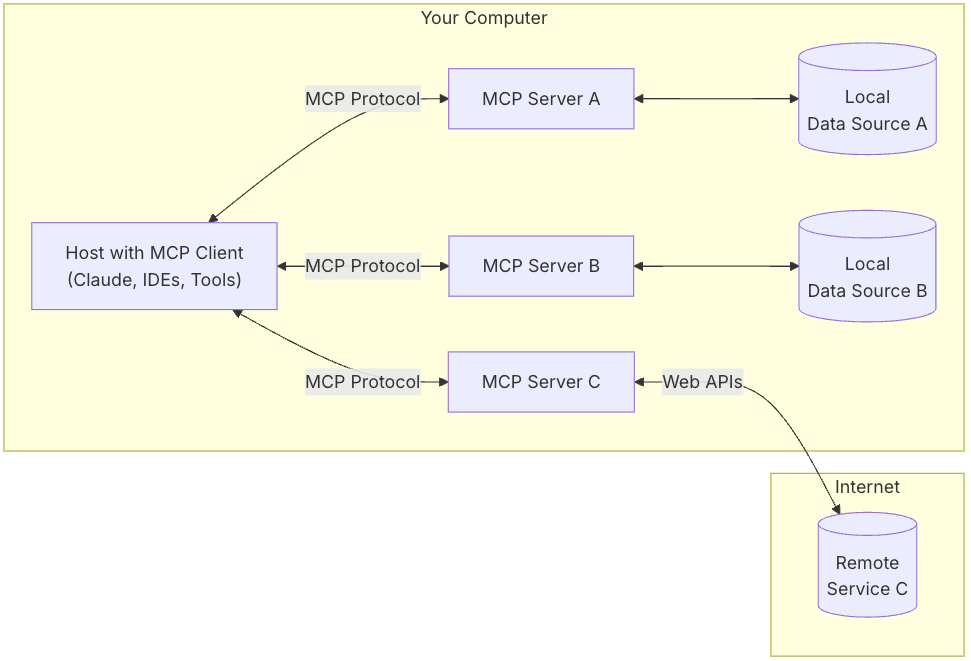
Diagram of an MCP connection. Clients send requests to servers, using MCP protocol.
In the examples we'll be looking at, our host is Claude Desktop, which includes an MCP client environment, and our server will be the Umbraco MCP server, which will connect out to our Umbraco instance.
MCP uses JSON-RPC v 2 to standardize how messages are sent between a client and a server. Within this, the protocol allows the server to define for the client what it can do by exposing 3 types of primitives:
- Tools are the functions that an AI can call to perform actions
- Resources are data that the AI can integrate into its knowledge base for responses
- Prompts are templated AI prompts that can be exposed to provide guidance on how to use the server
There are already loads of MCP server implementations for most of your favorite services. Most of these are simply using existing REST APIs and wrapping them in the MCP protocol for consumption within GPTs.
Putting It To Use
While all of that is pretty complex, the great thing is that you don't really need to understand it that deeply to make good use of it.
To add capability to an AI tool that supports it, you just need to find one you want to use and install it in your tool. While you can certainly just search for "[name of service you want] MCP server", there are a number of directories like PulseMCP that keeo a growing list of available server packages.
Note that, as always, you should think about privacy and trust. You're about to run your privileged information through someone else's code, so consider your source and what you allow access to.
MCP servers can run locally on your machine within the process of your host tool, or externally on another server.
For most use cases, I would recommend downloading and running local MCP servers. While there are some services out there that steer you to remote hosting, you will probably be configuring the MCP server with private credentials and permissions that are best kept to yourself, unless you really understand and trust where the code is hosted.
Claude Desktop, Visual Studio Code, Cursor, and Claude Code all provide instructions on how to install MCP servers within their tools.
AI-powered CMS
So with this new capability available, let's take a look at some of the things we can do when we add the Umbraco MCP to our AI toolkit. In these examples I'm running the MCP locally within Claude Desktop, and I've configured it per the instructions on Github to point at a newly-installed copy of Umbraco 16.
First, let's use it to skive out of our content modeling work. In the example video below, I'm pointing it at an existing webpage running somewhere else, and asking it to create a new document type in Umbraco that would be able to model that kind of page.
A couple of interesting things to note here:
- Based on the request, Claude is using it's builtin
fetchMCP and our providedumbracoMCP to get the HTML for a page on the Internet, and then inferring what the document type should look like. When it starts it doesn't really know much about Umbraco, but it queries the AI until it finds the right sort of data types to store the things it needs to. - I intentionally left my instructions pretty vague as a test. It included some very reasonable fields for summary and author information that weren't visible on the extracted page, but were entirely reasonable needs in a News Article.
- You'll notice that the LLM asks me to approve the use of each tool provided by the Umbraco MCP before it continues.
Now that we have a News Article, let's set up a quick blog and populate it. In this example, I'm using the builtin files MCP to reach into a folder on my computer desktop and grab a set of Markdown files. These just have the text of some articles; I'm asking the LLM to create all of the other fields. In order to give it some guidance, I first entered a prompt to give it a little context about the website and the organization it supports so it can come up with some proper SEO. (Note that I've sped up part of this video; the real time was around 8 minutes.)
The interesting bits here:
- At no point did I have to clarify that the source was in Markdown and the target was HTML. The AI was able to infer that and did the conversion as it worked. In general, LLMs seem to be very good at working with Markdown as a format.
- If you watch its reasoning chain, you can see that it pulls the one existing news article in my news folder from Umbraco. This helps it understand the structure of the articles it's about to enter. In general, LLMs seem to give better results when asked to repeat something they have an example of vs coming up with something new out of whole cloth.
- You can see with one of the articles, it made a mistake in the structure of the API, resulting in an error from the Umbraco API. It uses the error to correct its format and retry without intervention.
Buckle your seat belt, Dorothy, 'cause Kansas is going bye-bye
This is really just scratching the surface with a basic migration example. If you think about all of the tasks you complete as an admin or an editor in a CMS on a day-to-day basis, you start to see that almost all of them can be quickly automated using AI.
Further, we can even complete tasks that don't get done now because they're too time consuming.
- "Translate my blog posts into German"
- "Create a LinkedIn Post from my latest product"
- "Suggest edits to this page to make it more persuasive"
- "Go through my photos folder and sort it into subfolders based on whether the subject is of a person, place, or object. Add alt text for any that don't have it."
- "Pull this week's contact form submissions and add any asking about estimates into Hubspot. Put the others in an email to Mitch."
When you think about the capability that this adds, you start to realize that in a couple of years, the way we use CMS will look almost nothing like the way we use it today! (the same goes for the web in general, but that's another article)
In the short term, I expect CMS solutions in general to become more commoditized. CMS systems have always been "sticky": once you build your whole website around a platform and throw a few thousand pages in there, switching to something else becomes too painful. If we can reduce the pain of migration by automating most of it, then the switching cost can be reduced to the point that it's no longer reasonable to keep using something that doesn't meet the need well, or has too high of a license fee. An AI with an MCP can do exactly that, and a coding tool using an MCP can even help with the code migration.
In the longer term, I would expect the need to directly interact with the CMS itself to be reduced, or in many cases go away entirely. Many web projects today involve taking an existing content creation workflow and converting it to use the CMS so that we can have structured content. But if the structure can be inferred, why not keep using GDocs, or Office, or even email to keep that existing workflow? And just have the content migrate itself up to the website automatically?
It's an uncertain time to work in technology, but we're also on the verge of some amazing new capabilities. Think about the steps you take in your work day to day, and you'll probably find some great opportunities to automate them in a way that wasn't possible before. Now that we've ridden out the hype cycle, it's time to use agentic tools to get down to real work, and that's exciting.